Can a Weekend + LLMs Produce a New Neural Solver for the Quadratic Assignment Problem?
Weekend project with LLMs.
Motivation
LLMs have gotten surprisingly competent at the core task of research projects: reading papers, writing code, and turning messy thoughts into structured text. That naturally raises a question I couldn’t stop thinking about:
If I compress the entire research loop into a single weekend—survey → idea → implementation → experiments → write-up—how far can I get with LLMs as a co-pilot?
This post is that experiment.
I’m going to try it on the Quadratic Assignment Problem (QAP): an NP-hard optimization problem that’s notoriously hard. QAP is a “permutation” problem (like TSP), but the objective is quadratic, choices interact with each other in a way that quickly becomes globally entangled. Many well-known combinatorial problems can be expressed as special cases or close relatives of QAP, including variants related to routing, matching, layout, and assignment.
Despite that importance, QAP has received much less attention in neural combinatorial optimization than problems like TSP. One reason is practical: QAP is harder to “package” into the neural architectures that work nicely for other permutation problems. The signal you need depends on a lot of pairwise interactions, so learning good local decisions from partial context is simply harder. I’ll unpack this properly later, because it’s exactly where a new model design might help.
So the goal is simple and slightly reckless:
Can I, with the help of LLMs, produce a working neural method for QAP in a single weekend? And if I can, how competitive will it be? We’ll find out.
Preliminaries
Before diving into the sprint, a quick note on how I’ll run it.
This is a time-boxed project: the point is not to claim a polished, state-of-the-art solver, but to see what kind of research artifact can be produced under extreme constraints with modern LLM support. The output I’m aiming for is:
- a working implementation,
- a reproducible experimental setup,
- and a coherent write-up (call it a short paper or technical report).
I’ll use the following tools:
- ChatGPT (GPT-5.2 Thinking) for quick literature scanning, problem framing, and architecture brainstorming.
- Codex (gpt-5.3-codex) for coding iterations and refinements.
- Prism (LLM-assisted LaTeX projects) for the final report formatting.
Let’s start.
Stage 1: Literature Review
Before reading papers, I wanted to make sure I had the QAP formulation fresh in my mind. It’s been a while, so I simply asked the LLM for a quick refresh.
Q. Remind me of the Quadratic Assignment Problem (QAP) formulation.
A. The Quadratic Assignment Problem (QAP) assigns $n$ facilities to $n$ locations. Let:
- $F \in \mathbb{R}^{n\times n}$ be the flow matrix, where $F_{ij}$ quantifies the interaction between facilities $i$ and $j$.
- $D \in \mathbb{R}^{n\times n}$ be the distance matrix, where $D_{ab}$ is the distance between locations $a$ and $b$.
- $\pi \in S_n$ be a permutation, where $\pi(i)$ is the location assigned to facility $i$.
The QAP objective is:
\[\min_{\pi \in S_n} \ \sum_{i=1}^{n}\sum_{j=1}^{n} F_{ij}\,D_{\pi(i)\,\pi(j)}.\]Equivalently, using a permutation matrix $P \in {0,1}^{n\times n}$ with $P_{i,\pi(i)}=1$ and the feasible set $\Pi$ of all permutation matrices:
\[\min_{P \in \Pi} \ \langle F,\ P D P^\top \rangle,\]where the Frobenius inner product is:
\[\langle A,B \rangle = \sum_{i=1}^{n}\sum_{j=1}^{n} A_{ij}B_{ij}.\]Next, I asked the LLM to do what I’d normally do first: a fast literature scan, focused specifically on neural / deep learning methods for QAP.
Q. Give me a concise literature review of deep learning approaches for the Quadratic Assignment Problem (QAP): main method families, key papers, benchmarks/baselines, and the most promising gaps to explore.
A. (Literature review.)
After a fairly broad scan (24 minutes, 277 sources), it returned a structured summary and a handful of recent papers that were new to me.
| Paper / year (real title) | Cite | Short description |
|---|---|---|
| Revised Note on Learning Algorithms for Quadratic Assignment with Graph Neural Networks (2018) | Supervised GNN method trained on synthetic/planted regimes to learn QAP-like assignment behavior (primarily studied outside “full” QAPLIB facility-layout evaluation). | |
| Neural Graph Matching Network: Learning Lawler’s Quadratic Assignment Problem With Extension to Hypergraph and Multiple-Graph Matching (2019; TPAMI 2022) | Association-graph neural matching + Sinkhorn projection to predict permutations for Lawler-QAP / graph matching; extends to hypergraph and multi-graph matching settings. | |
| Solving the Quadratic Assignment Problem using Deep Reinforcement Learning (2023) | Constructive RL for Koopmans–Beckmann QAP using an alternating “double pointer” style policy over facilities/locations, trained with actor–critic. | |
| Revocable Deep Reinforcement Learning with Affinity Regularization for Outlier-Robust Graph Matching (ICLR 2023) | RL-based solver for Lawler-QAP/graph matching with outliers; uses revocable decisions and affinity regularization to improve robustness to unmatched nodes. | |
| Learning Solution-Aware Transformers for Efficiently Solving Quadratic Assignment Problem (ICML 2024) | Learn-to-improve transformer that conditions on the incumbent assignment (“solution-aware”) and outputs swap-style improvement actions; evaluated on synthetic KB-QAP and QAPLIB generalization. | |
| Unsupervised Learning for Quadratic Assignment (2025) | Unsupervised permutation learning (no solved targets) to generate strong initial solutions that are refined by tabu search; studies instance-regime and size variation. | |
| BiQAP: Neural Bi-level Optimization-based Framework for Solving Quadratic Assignment Problems (KDD 2025) | Bi-level framework where a network guides a differentiable entropic relaxation (inner solver) while optimizing the original QAP objective at the outer level. | |
| Learning the Quadratic Assignment Problem with Warm-Started MCMC Finetuning and Cross-Graph Attention (ICLR 2026 submission) | Cross-graph attention + warm-started MCMC finetuning/adaptation at inference time; energy-based formulation for efficient swap proposals and runtime–quality tradeoffs. |
For this project, I want to isolate what a neural policy can do without leaning on an external metaheuristic. Those hybrid pipelines are often excellent in practice, but they also blur the real potential of a neural solver, treating it as a neural component inside a classical solver.
So I’ll treat the following as hybrid baselines rather than the main object of study:
-
(explicit tabu-search backbone; the network primarily provides an initialization)
-
(explicit inference-time MCMC finetuning/adaptation)
Instead, the most relevant direction for me is the learn-to-improve family, especially
I’ll start from methods with public code so the comparisons are not based on re-implementations:
-
—
alexnowakvila/QAP_pt -
—
Thinklab-SJTU/ThinkMatch(NGM model folder) -
—
psbagga17/drlqap -
—
Thinklab-SJTU/RGM -
—
PKUTAN/SAWT
A key point already shows up here: these baselines actually split into two partially different “QAPs” in practice:
- facility-layout / Koopmans–Beckmann settings (often geometry-structured),
- Lawler-QAP / graph matching settings (affinity-driven, association-graph flavored).
Stage 2: Gaps within Neural QAP
The literature report came back with the usual “checkbox gaps”: scalability beyond small $n$, generalization to QAPLIB, hybridization with exact solvers, lack of standardized benchmarks, and a “theory and guarantees” bucket (help!). All true, but also a bit too generic.
What I did take seriously is the evaluation angle. Seems like QAP papers often look hard to compare because each one uses different evaluation protocols: different instance generators, different time budgets, different baselines. So rather than jumping straight into model design, I decided to first produce a clean benchmark + reproducible baselines.
That said, I didn’t want this weekend to become an exercise of reviewing theoretical proofs, or re-implementing plain tabu search for the tenth time. My point is to explore something algorithmic: a representation choice, an inference procedure, or a learning pipeline that is genuinely better aligned with QAP’s structure.
So I asked the LLM again:
Q. Ignore generic “future work” (scale, more benchmarks, theory). Based on existing neural QAP methods, list 5–8 specific, mechanism-level gaps and a concrete improvement for each.
A. It came with a bunch of interesting gaps, here the most interesting ones in my opinion:
-
“What problem are we solving?” (KB-QAP vs Lawler-QAP mismatch). Several neural papers labeled as “QAP” are really solving different formulations (layout-flavored KB-QAP vs matching-flavored Lawler-QAP). This makes comparisons misleading unless the benchmark is explicit about which regime it targets. Some neural pipelines implicitly rely on coordinates and Euclidean geometry (a habit from TSP). In QAP, and particularly in QAPLIB, $D$ is often just an arbitrary cost matrix (grid/manhattan, random, structured, etc.), so a coordinate-based inductive bias can break silently.
-
Association-graph materialization blows up memory. Methods that build the full association graph quickly hit GPU-memory limits as $n$ grows, making large QAPLIB instances impractical.
-
Constructive RL tends to be underpowered unless it gets strong structure priors. Constructive decoders face hard credit assignment because early choices interact quadratically with everything that comes later. This is visible in small-$n$ RL papers that do not scale cleanly.
-
Additive scoring/energy misses quadratic coupling. Surrogates that score assignments as $\sum_i \phi_{i,\pi(i)}$ cannot represent the true quadratic interactions, biasing move ranking and exploration, especially on dense instances.
-
Sparse/ambiguous reward in learn-to-improve RL. Treating non-improving steps as “zero signal” (and not explicitly penalizing worsening moves) makes plateaus look identical and wastes steps under tight budgets.
Stage 3: The Proposal: Architecture and Training/Inference Recipe
Before touching model design, I implemented the classical baselines (greedy construction + swap local search), neural baselines (RGM
A minimal neural-improvement starting point
The first neural baseline is deliberately simple: a swap-based neural improvement policy.
- State: an incumbent permutation $\pi$ (starting from a sequential initialization).
- Action: choose a swap $(i,j)$ and apply it.
- Rollout: fixed horizon of $T=4$ steps.
- Training: RL on improvement trajectories (Normalized improvement over $T$ steps as reward).
The main design question then became: what inductive bias should the policy have to pick good swaps reliably?
Instead of trying to design the final model in one shot, I iterated quickly with a coding agent: propose a modification, implement, train a short run, keep the changes that improve the validation curve.
Below is a compact log of the most informative iterations (validation on 100 instances of size $n=5$, reporting the best gap to optimal % after 20 steps).
Iteration log
1) Baseline swap policy (trained on $n=5$)
Result (gap to optimal @ $n=5$): 1.8522%
What it is: a basic swap policy trained end-to-end with RL, without strong QAP structure injected.
2) Min–max instance normalization
Result (gap to optimal @ $n=5$): 1.6824%
Change: normalize the instance matrices (flow and distance) with min–max scaling.
Why it helped: reduced sensitivity to absolute scale and improved optimization stability.
3) hetero_rel_transformer (2$n$ heterogeneous tokens + relational attention)
Result (gap to optimal @ $n=5$): 1.5965%
Change: represent each instance with 2$n$ tokens:
- $n$ facility tokens + $n$ location tokens,
and inject instance structure via relation-biased attention (flows on facility–facility edges, distances on location–location edges, assignment links on cross edges).
Why it helped: forced the policy to treat QAP structure as pairwise relations rather than flat features.
4) hetero_rel_transformer v2 (solution-aware relations + stronger attention control)
Result (gap to optimal @ $n=5$): 1.1659%
Changes (core ones):
- add induced distance $D_{\pi(i)\pi(j)}$ as a first-class relation feature,
- add per-head gates that balance content attention ($qk$) vs relation bias,
- optionally modulate value aggregation with relation features.
Why it helped: made the encoder explicitly solution-aware in the same way swap delta computations are.
5) +1 dual-encoder layer (facility-only + location-only pre-encoding)
Result (gap to optimal @ $n=5$): 1.0301%
Change: before the 2$n$ hetero encoder, run a small “static” encoder:
- facility-only attention over $F$,
- location-only attention over $D$,
then fuse these static embeddings with the dynamic (solution-conditioned) tokens.
Why it helped: improved token quality by encoding within-type structure (flow communities, distance geometry) before mixing types.
6) Pre-norm GTLayer + relation features as both bias and gate (e1/e2)
Result (gap to optimal @ $n=5$): 0.6666%
Change: switch the main layers to a pre-norm transformer where relation features affect attention in two ways:
- e1: additive bias on attention logits,
-
e2: multiplicative gate on attention probabilities (relation-conditioned filtering).
Why it helped: the model can learn both which relations matter (gate) and how strongly (bias), which is closely aligned with swap evaluation.
7) +3 static (pre) layers (stronger dual encoder)
Result (gap to optimal @ $n=5$): 0.5694%
Change: deepen the static pre-encoder (3 layers).
Observation: more capacity helps in-distribution, but can start to over-specialize and hurt out-of-distribution generalization.
8) hetero_rel_transformer_3n_assign_pairwl (3$n$ tokens + explicit assignment tokens + pairwise reasoning)
Result (gap to optimal @ $n=5$): 0.3677%
Change: move from 2$n$ to 3$n$ tokens by adding an assignment token $A_i$ for each facility:
- $F_i$ (facility token), $L_a$ (location token), and $A_i=(i,\pi(i))$ (current assignment token).
Then decode swaps with a pair-state module (PairWL): an approximate 2-WL-style update over assignment-token pairs $(i,j)$ using triadic composition $\sum_k (i,k)\circ(k,j)$.
Why it helped: swap choice is inherently pairwise; making pair structure explicit reduces the burden on facility embeddings.
9) --pairwl_use_token_feedback
Result (gap to optimal @ $n=5$): 0.3128%
Change: add pair-to-token feedback, pooling pair states around each assignment token and writing back into token embeddings.
Why it helped (and hurt): improves in-distribution consistency, but can increase coupling and reduce robustness when scaling.
10) --pairwl_use_relation_aware_triad + --pairwl_use_strong_token_feedback
Result (gap to optimal @ $n=5$): 0.2972%
Changes:
- make the triadic composition relation-aware by gating intermediate nodes $k$ using learned functions of local pair features,
- strengthen the token feedback pathway (optionally top-$k$ pooling).
Why it helped: pushes the pair module closer to swap-delta reasoning, where triadic context is filtered by instance- and solution-dependent cues.
To summarize the effect of these design iterations, the next Figure shows the best validation gap found on 20 steps (on $n=5$) after each architecture update.
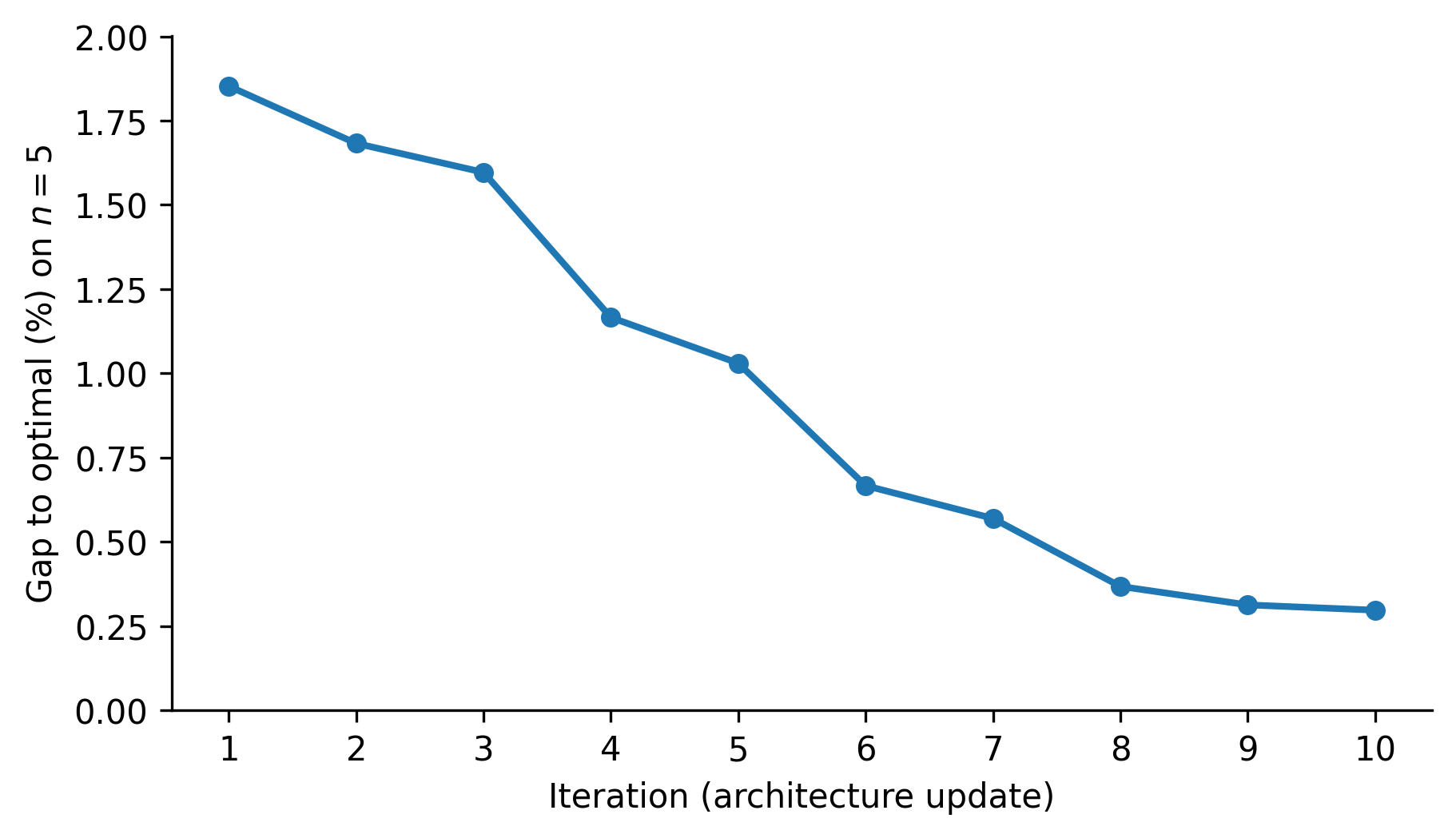
What I take from these iterations
1) The best improvements came from features that mimic how swap local search evaluates moves:
- induced distances under the incumbent ($D_{\pi(i)\pi(j)}$),
- strong control of relation influence (bias + gate),
- explicit pair reasoning when decoding swaps.
2) Extra capacity helps, but only if it reinforces the right structure.
The 3N + PairWL variants are slower, but they improved generalization markedly at larger $n$ under the same step budget.
In the next stage, I’ll formalize the evaluation protocol and compare these variants against the basleines under consistent budgets.
Stage 4: Experiments and Evaluation Protocol
After several architecture iterations, the next step is to evaluate under a more realistic protocol: more test instances, multiple sizes, and direct comparison against both learned and classical baselines.
We use our model trained exclusively on instances of size $n=5$. However, we will now evaluate their generalization to larger sizes: $n \in {5,10,15,20}$.
Baselines
We compare against four baselines that cover both “neural” and “classical” points of reference:
- Learned baselines: RGM (neural constructive trained on $n=20$) and SAWT (neural improvement trained on $n=20$).
- Greedy constructive: a simple non-learned heuristic that builds a permutation once.
- Swap local search: a classical improvement baseline operating in the same 2-swap neighborhood, run until getting stuck in a local optima.
We report anytime performance (best-so-far objective versus time).
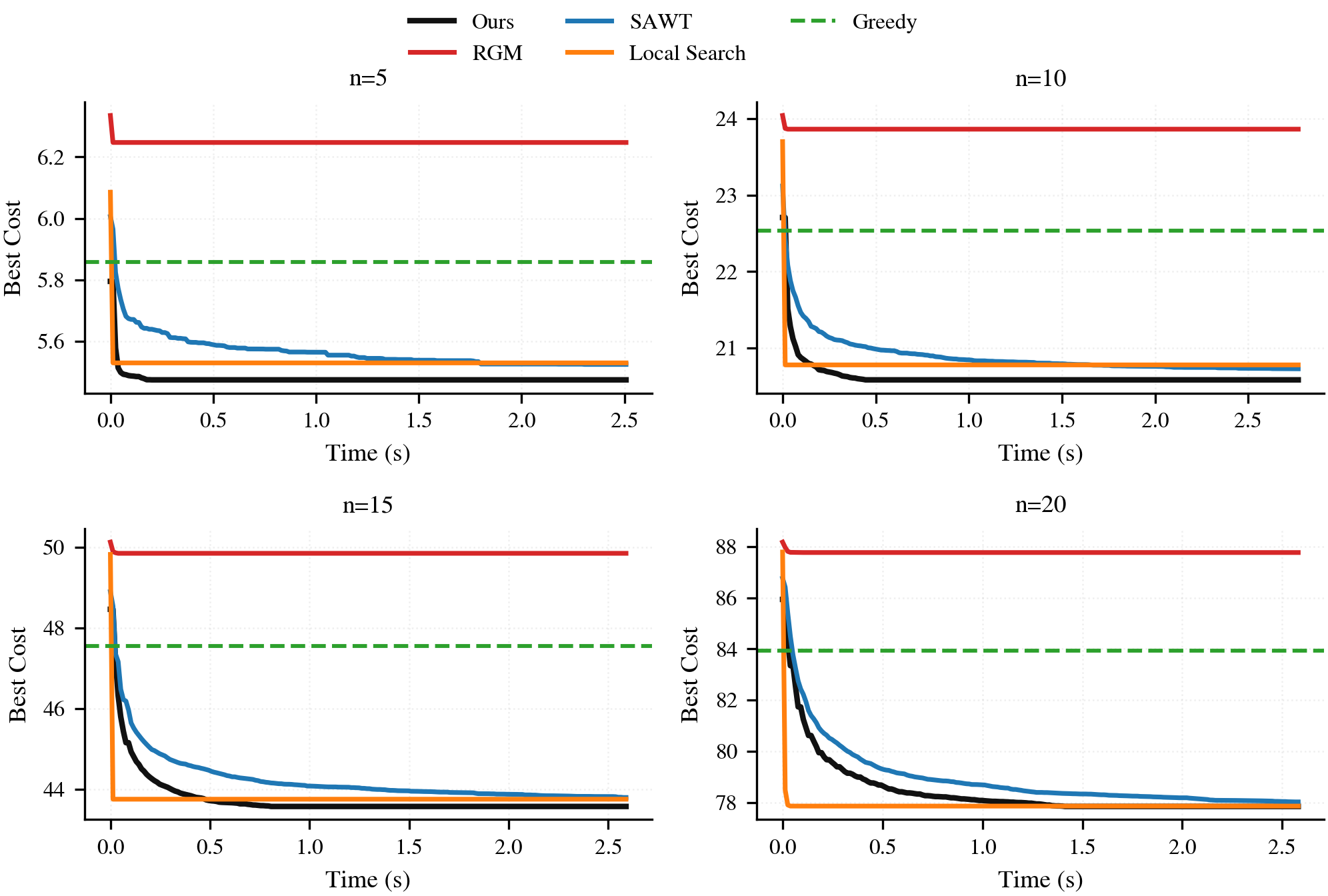
Results show a clear pattern: the policy trained on $n=5$ remains competitive on $n=5$ and exhibits non-trivial transfer to larger sizes. Under the same evaluation budget, it achieves the strongest final objective among the tested baselines, indicating that the improvements learned in the small regime are not purely size-specific.
Stage 5: Wrapping up
I did not expect the final outcome to look this strong.
The most surprising part is not that a neural model can learn to propose useful swaps, that is plausible in hindsight, but that the iteration loop was fast enough to make that progress in a couple of days. In the past, I had explored similar ideas, but the cost of implementation details (plumbing, debugging, profiling, refactors) made each iteration way longer. Ideas accumulated in unfinished branches and abandoned folders, long before reaching a clean evaluation protocol.
This time, the workflow was different: iterate on the architecture and training loop quickly, validate with a tight benchmark, keep only the changes that move the curve. That speed changes what is feasible.
There is a trade-off, though. Delegating implementation to a coding agent reduces friction, but it also reduces direct contact with every line of code. That loss of “full manual control” is not free: it can hide bugs, bake in unexamined assumptions, and make it easier to mistake artifacts for progress. The right posture is to embrace the speed while staying disciplined about verification.
I initially planned to end with a short, paper-like write-up, but the results were promising enough to justify a more complete treatment. Instead, I’m turning this into a proper article: cleaner experimental design, stronger baselines, and a thorough set of benchmarks and ablations to pinpoint what actually drives the gains. More soon.